
By: Josiah Huckins - 1/18/2022
minute read
I run a few low powered but feature rich pi servers, as I like a little independence in my apps/services. There's nothing wrong with hosting on Azure, AWS and the like, but its nice to have certain things hosted in a private cloud where you have more control. Not to mention, the cost can be reduced without sacrificing resource allocation (to an extent of course).
Numerous services are appropriate for private clouds: blog sites, personal digital asset management, home automation, code editing/compilation, crypto mining, and more. Installing and configuring an app host's OS or building the IaC to do so requires a lot of time. Once you've built the app and have it in a stable working state, the experienced engineer knows the very next thing to do: back up that stable state!
Phase 1: Full Base Image Backup
By stable state we mean the app/service works as intended under the current configuration and software versions. This is subject to change as the service or infrastructure are upgraded. Reliability is not always guaranteed, so its important to have a means to fully recover that stable state.Enter phase 1 of my backup process, a bit for bit clone of mass storage devices. As mentioned, I run my services on little pi servers. The storage on these devices are class 10 high capacity SD cards. The MTBF of SD cards is hard to pinpoint. It depends on how often they're used, especially for writing. One thing I've heard from multiple sources is that they're expected to have a reliable lifespan of a few years. A safe estimate is 2-3 years for servers that are in constant use. With that in mind, its crucial that I have backups on hand to restore them.
Now as to the bit for bit cloning, I rely on the trusty dd command. DD is a data copy utility that ships with most linux distros. (I've seen it on every linux variant I've come across.) Obviously, to clone an SD card you need a device with more free space available than the size of the card.
First, gracefully shutdown any services you're running, then turn off the machine.
Insert the card in a card reader on another machine running linux (or a live CD). Linux uses the /dev filesystem abstraction to store references to mass storage devices. You can determine which item under /dev is the SD card by running:
lsblk
You should see a size column in the output, which should allow you to determine which device it is, based on the value. With the device determined, create a backup image via the following terminal command (replace sda with the name of the SD card device):
sudo dd if=/dev/sda of=base-image-backup.zip status=progress
It may take some time to finish. Get coffee, play a game with your kids and then come back to continue. Once the backup has been created, put the SD card back into your server and boot up the host. I recommend storing the backup in 2 locations, one being an onsite NAS, the other a cloud storage provider of choice. Having multiple locations for the backup isn't paranoia, its the only real way to ensure redundancy in case of disaster. As the Navy Seals say, "Two is One, One is None". As mentioned, this base image is useful if you need to restore to an initial working state. Onto phase 2.
Phase 2: Automated Ongoing Backups
Good planning of your application architecture will help in this phase. As often as possible, I try to follow a model of running apps that can be containerized, accessing them from a browser or android webview. On the host, I put all the source files and volumes in a central directory. This makes it trivial to compress and move all the apps to a secondary location.Setup and Getting the Script
From my home directory, I made a backup folder via:mkdir ~/backup
This folder should only be used to stage content for backup to a cloud storage provider, so I set specific permission bits so only the backup user is able to update it. The folder should be owned by your backup user as well:
chmod 700 backup
The cloud storage service we're using for this tutorial is Dropbox. At the time of writing, Dropbox doesn't provide an executable client for ARM architectures, but that doesn't matter as we can use a shell script and invoke their API to upload our files/folders. To obtain the script (spoiler alert, I didn't write it), first make sure you have git installed:
sudo apt-get update && sudo apt-get upgrade
sudo apt-get install git -y
Then as your backup user, obtain the script via:
git clone https://github.com/andreafabrizi/Dropbox-Uploader.git
(Credit to Andrea Fabrizi for creating and maintaining this repository and the script!)
With the script downloaded, we need to make a brief edit to ensure the settings are created in our backup folder (the default location is your home directory). Move into the backup directory, then copy the dropbox script there, from the git project you just cloned:
cd ~/backup
cp ~/Dropbox-Uploader/dropbox_uploader.sh .
Now open this script in your IDE or text editor of choice and locate the CONFIG_FILE constant, it must be the first occurence. Change the value after the equals sign to include the path to your backup folder:
CONFIG_FILE=~/backup/.dropbox_uploader
Save and close the file. You are about ready to run the script for the first time, but before that we need to have a little fun with OAuth.
Dropbox App/API Key Setup
Upon first run of the script you'll be prompted to set up OAuth client access for the script, so it's authorized to make updates to your storage, on your behalf.To enable this you need to go to this Dropbox developers page to create an app. On that page, you'll see something similar to:
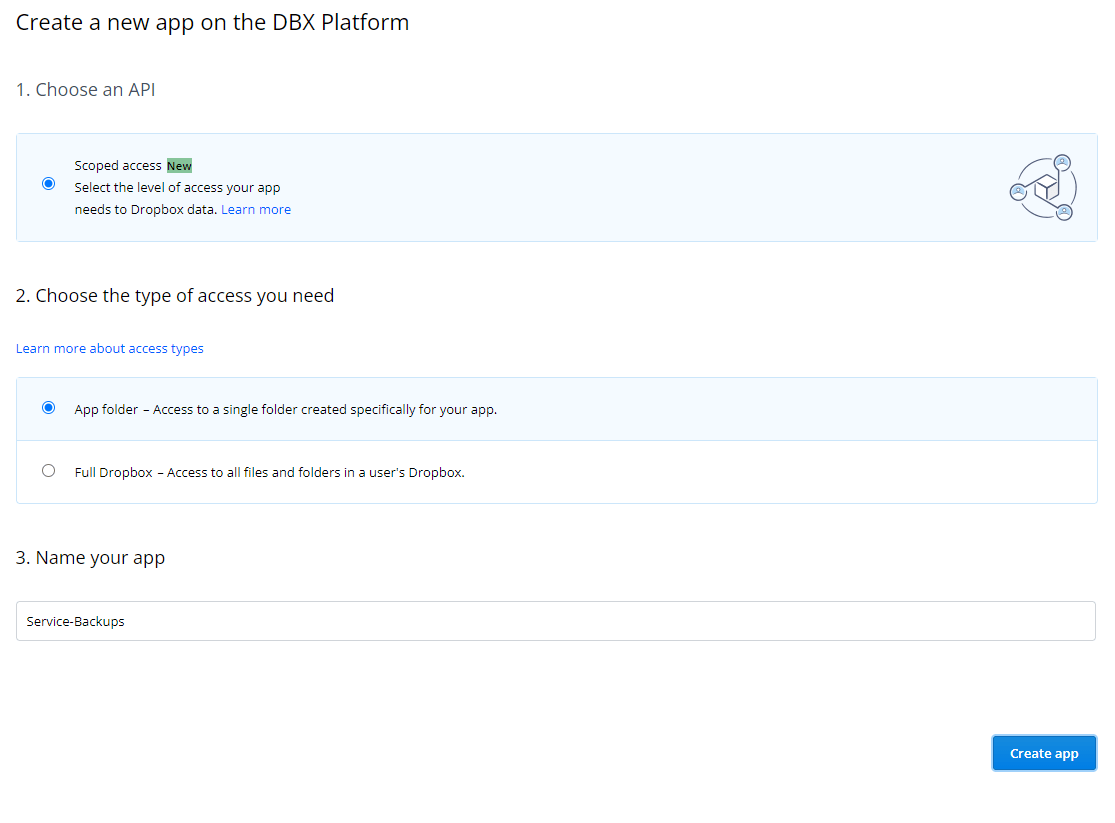
Select the scoped access API in step 1. In step 2, I selected the full dropbox access type. At the time of writing, this is required for writing the backups to a pre-created folder. The app folder access type may be preferred if you want to limit access to a single app folder. You also have options (see below) to limit the scope of access to a one way only push (write) of data into your dropbox account.
Finally, give your app a name (I chose Service-Backups), and click/tap Create app.
With your app created, you should immediately be taken to the apps configuration page. From this page you can configure a number of different things. For this tutorial, we only want to focus on setting access scopes and obtaining our api key and secret.
First go to the Permissions tab. Here you can configure and limit the access your sync tool has to Dropbox. I only allow mine file and folder write access, but you can grant additional scopes if preferred. With this defined according to your preferences, go back to the Settings tab.
You should see an App key and App secret on this page (you may need to show the secret). These are the values needed in the dropbox_uploader script the first time it's run. You should now be able to run the dropbox_uploader.sh script which you copied into your backup folder:
./dropbox_uploader.sh
When running the script the first time, you'll be prompted first for your Dropbox app key, followed by the app secret. The script should then provide a link to navigate to in your browser, for obtaining an access code.
Use this URL https://www.dropbox.com/oauth2/authorize?client_id=app key&token_access_type=offline&response_type=code, replacing "app key" with the value of your own app key. Dropbox will ask you to confirm that you trust the developer. If you click/tap continue, you'll then be able to allow the script access to your Dropbox, via the access scopes defined earlier. Once allowed, you will see an access code. This is the OAuth access code you need to provide to the script when prompted. After providing the access code, the script will ask you to confirm the values for your app key, app secret and access code. Make sure these values are correct so the script can authenticate and push backups. Once confirmed, the setup is complete and you are ready to run the backups.
Running Backups
Let's go over the script syntax really quick. The script has a number of commands you can review by running it without any arguments:./dropbox_uploader.sh
We really only care about the upload, list and delete commands for our use case.
The upload syntax is straightforward, for example to upload a file:
upload ~/backup/backup.tgz backups/priv-cloud/some-service
Delete is even simpler:
delete backups/priv-cloud/some-service/backup.tgz
We can upload backups and clean out old ones, neat!
To make this all the more easy, we can use a small script I wrote to create a compressed file containing all the areas of the server we want backed up. This doesn't include the entire system (we have the full backup from phase 1 for that), just the directories we need to restore the services we're running.
The script syntax is: ./backup_runner.sh optional argument 1: service name, optional argument 2: a custom backup location in Dropbox under a root /Backups folder, optional argument 3: backup retention - how many days the backup should be kept for, where the service name may be anything you want to name the backup, to distinguish it from other services you're backing up. This assumes you have a "Backups" directory in the root of your Dropbox. The backup is created with today's date, which is also used in determining whether to keep or remove the backup with future script runs, when backup retention is enabled.
You could run this manually, or better yet via a scheduled job. The following cron expression will schedule the backup to run every other day at 1 am (server time), removing the oldest backups after 10 days:
0 1 1-31/2 * * /bin/bash /home/pi/backup/backup_runner.sh Some-Service /priv-cloud/services 10 >/dev/null 2>&1
If you need to test the cron job, don't get tripped up by time differences. Unless you've configured your server's time settings, chances are its not in the same GMT time zone as your location. You can check the server's time via:
date "+%T"
If the output of this differs from your local timezone, adapt accordingly when testing.
Note, for best results you'll want to add the cron entry to the root user's crontab file. The script is designed to create the backup using the root user and then complete the upload to Dropbox as your backup user (just pi in my example). If you have a separate backup user, you'll need to update these lines in the backup-runner.sh script with the name of that user account:
sudo -u pi ./dropbox_uploader.sh upload backup-${1}-${date}.tgz Backups${2}
sudo -u pi ./dropbox_uploader.sh delete ${backupsLocation}/backup-${1}-${backupEntryDate}.tgz